
Auto-Increment vs UUID for Relational databases
When I first learned ERD design for SQL databases, the default primary key choice was a sequential integer. Later, while building my first production backend, I discovered UUIDs. At the time, they felt like a more sophisticated solution because of their randomness and uniqueness. What I did not realize then was that UUIDs, especially UUIDv4, can become silent performance killers.
As systems scale, teams often encounter unexplained write slowdowns and rapidly growing index sizes. These issues become even more noticeable once an application outgrows a single server.
The choice between auto-increment integers and UUIDs is far more than an API design decision. It directly impacts how data is stored and indexed. Most modern relational databases rely on B+ trees, and the structure of your primary key heavily influences how efficiently those trees operate. In practice, neither sequential integers nor UUIDv4 are the ideal solution. There is a third option that delivers the best of both worlds.
Let’s take a closer look at what happens under the hood.
How databases store primary keys
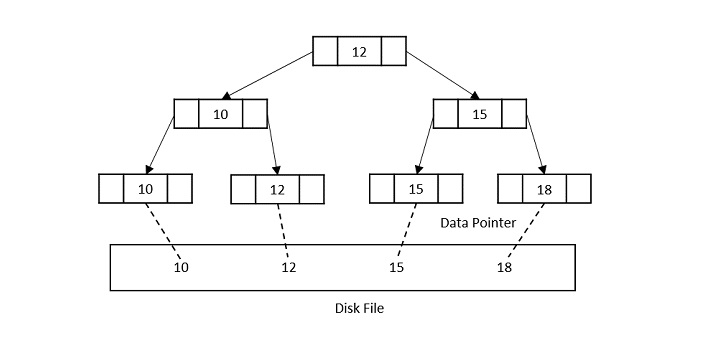
Relational databases store primary keys in a B-tree. Think of it as a sorted tree structure spread across fixed-size memory pages on disk. Every time you insert a row, the database has to figure out where in that tree the new key belongs, navigate to the right page, and write it there.
That last part, finding the right page, is where your choice of primary key starts to matter.
Auto-incrementing integers
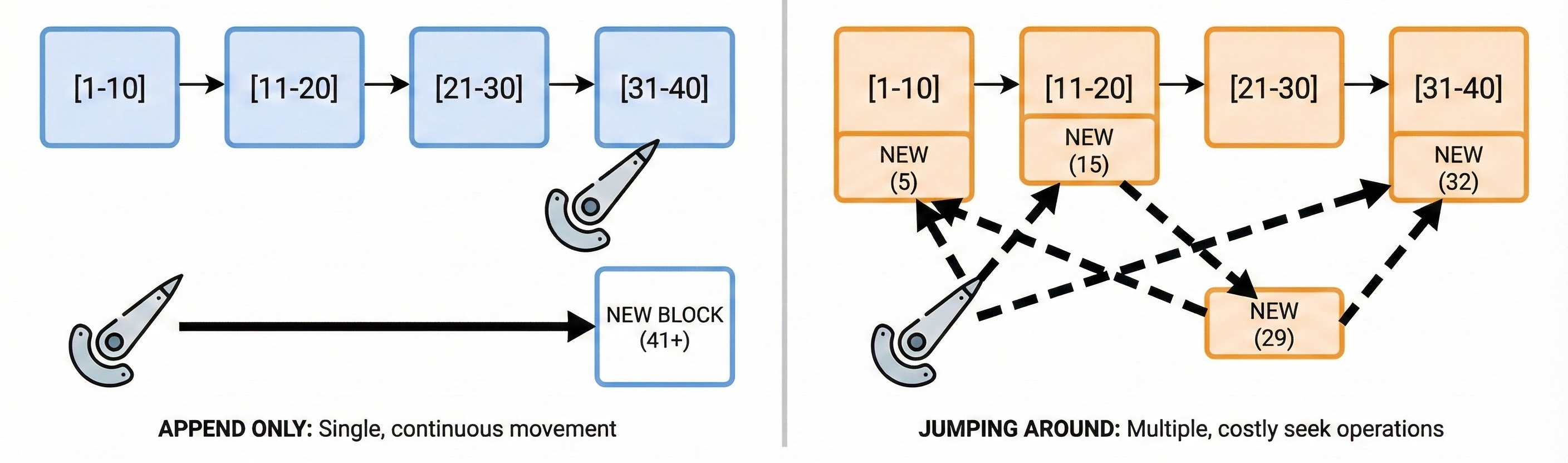
Sequential integers (1, 2, 3...) are always increasing. The next key is always larger than the last. The database knows exactly where to put it: the rightmost edge of the B-tree. No searching, no shuffling, just append and move on.
This is as fast as inserts get. The database writes to one hot page at a time, fills it up, opens a new one, and keeps going. Zero fragmentation. Minimal CPU overhead.
Storage is also compact. An integer takes 4 to 8 bytes. For a table with millions of rows and several secondary indexes (each of which stores a copy of the primary key), that adds up.
There are 2 main problems :
1. Integers are predictable
If your API exposes a user ID in a URL like /users/42, anyone can guess /users/43 exists.
This is called Insecure Direct Object Reference (IDOR). it is a real vulnerability if you are not doing authorization checks on every single endpoint. Most of the backends are not doing this perfectly. This seemingly simple vulnerability was left unseen, leading to recent CBSE website security was bypassed.
2. Collision in distributed systems
If you have multiple database servers all inserting rows at the same time, two servers could try to claim the same ID at the same millisecond. The fix is a centralized lock: one server is responsible for handing out the next integer. Every insert has to wait for that lock. At high write throughput, that lock becomes a serious bottleneck.
UUIDs (version 4)
UUIDv4 is a randomly generated 128-bit value. It looks like this: 550e8400-e29b-41d4-a716-446655440000. The number of possible UUIDs is large enough that collision is not a realistic concern. They are also completely unpredictable, which removes the IDOR problem entirely.
The problem is what random insertion does to a B-tree.
Because UUIDv4 values are random, each new insert lands somewhere arbitrary in the index. The page it belongs on might be full. When that happens, the database performs a page split: it divides the full page in two, physically moves half the data to a new page, updates the internal pointers, and then finally writes the new row.
Page splits are expensive. They consume CPU, generate disk I/O, and leave your index fragmented. Fragmentation means pages are only partially full, so the database reads more pages to find the same amount of data. Over time, on a write-heavy table with UUIDv4 primary keys, this compounds.
Storage is also larger. 16 bytes per UUID, versus 4 to 8 for an integer. Primary keys are copied into every secondary index, so on a table with five indexes, you are storing the key six times per row. On tens of millions of rows, that pushes data out of RAM and into slower disk reads.
You can read about UUID and page split in detail from this blog.
UUIDv7: the thing I wish I had known earlier
The real issue with UUIDv4 is not that it is a UUID. It is that it is random. The B-tree problem exists because there is no ordering to the values.
UUIDv7 fixes exactly that. It combines a Unix timestamp in the first half with cryptographically secure random bits in the second half.
Because the first half is a timestamp, UUIDv7 values generated at roughly the same time are sorted close together. The database appends them to the right edge of the B-tree, exactly like an auto-incrementing integer. Page splits disappear. The random suffix means they are still globally unique and completely unguessable. No central lock needed.
A UUIDv7 generated now looks sequential relative to one generated a second ago, but random relative to anything a user could guess.
You get sequential write performance with distributed-safe, unpredictable IDs.
Comparison at a glance
| Auto-increment | UUIDv4 | UUIDv7 | |
|---|---|---|---|
| Storage size | 4-8 bytes | 16 bytes | 16 bytes |
| Insert performance | Fast (sequential) | Slow (random, page splits) | Fast (time-ordered) |
| Distributed safe | No (requires central lock) | Yes | Yes |
| Predictable / guessable | Yes (IDOR risk) | No | No |
| Globally unique | No | Yes | Yes |
| Sortable by creation time | Yes | No | Yes |
Using UUIDv7 in Django
Django does not ship UUIDv7 support out of the box yet (as of writing). The cleanest approach is the uuid6 library, which implements both UUIDv6 and v7.
bashpip install uuid6
python# models.py import uuid6 from django.db import models class Post(models.Model): id = models.UUIDField( primary_key=True, default=uuid6.uuid7, editable=False ) title = models.CharField(max_length=200) created_at = models.DateTimeField(auto_now_add=True)
That is the entire change. uuid6.uuid7 is a callable that generates a new UUIDv7 on each insert. Django passes it as the default exactly like it would uuid.uuid4.
To see that UUIDv7 values actually sort by creation time:
python# Run in Django shell: python manage.py shell import uuid6 import time ids = [] for _ in range(5): ids.append(uuid6.uuid7()) time.sleep(0.01) print("Generated order:") for uid in ids: print(uid) print("\nSorted order (should be identical):") for uid in sorted(ids): print(uid)
The two lists will be identical. UUIDv7s sort chronologically, so ORDER BY id gives you insertion order without a separate created_at column.
The database does not care what your ID means to the application. It cares about where in the B-tree the new value belongs. Sequential values are cheap to insert. Random values are expensive. UUIDv7 is sequential enough for the database and random enough for your users.
The industry moved slowly on this because UUIDv7 only became an official standard (RFC 9562) in 2024. Most frameworks have not caught up yet, but the uuid6 library fills the gap cleanly.
Alternatives
UUIDs are not the only type of identifier that provides uniqueness within a distributed architecture. Considering they were first created in 1987, there has been plenty of time for other professionals to propose different formats such as Snowflake IDs, ULIDs or NanoIDs.
text# Snowflake ID 7167350074945572864 # ULID 01HQF2QXSW5EFKRC2YYCEXZK0N # NanoID kw2c0khavhql